|
|||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||
|
This task was aimed
at implementing an algorithm providing state of the art performance. As it
constitutes the input to any automated system, landmark identification should
be robust to surface artifacts so that it allows geometric normalization into
a common reference in a fully automatic manner. |
|
||||||||||||||||||||||||||||||||||||||
|
Combinatorial Search and Shape Regression |
|
||||||||||||||||||||||||||||||||||||||
|
We presented a
method for the automatic detection of landmarks for craniofacial research that
can handle missing points, allowing non-rigid deformations. Our algorithm,
termed SRILF (Shape Regression with Incomplete Local Features [Sukno 2012a]), receives a set of 3D candidate points for each
landmark (e.g. from a feature detector) and performs combinatorial search
constrained by a deformable shape model. A key
assumption of our approach is that for some landmarks there might not be an
accurate candidate in the input set. While many approaches try to retain
large numbers of candidates to make sure that at least one will be reasonably
close to the desired landmark position, SRILF determines the number of
candidates as an upper outlier threshold from the distribution of false
positives over a training set. This implies that, in the vast majority of
cases, a candidate that is close enough to the target landmark will be
detected, but a small proportion will be missed. Hence, for each targeted
landmark there will be an initial set of candidates that may or may not
contain a suitable solution and we need to match our set of target landmarks
to a set of candidates that is potentially incomplete. This is analogous to
the point-matching problem found in algorithms that search for
correspondences. However, the human face is a non-rigid object and these point-matching
algorithms are typically restricted to rigid transformations. We tackle this
by detecting partial subsets of landmarks and inferring those that are
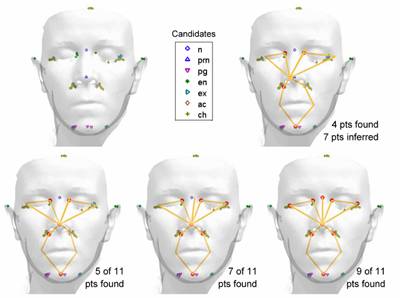
missing so that the probability of the deformable model is maximized. An indicative
example of the different steps is provided in Fig 1. The first step that is
displayed corresponds to a subset of 4 candidates that fulfils the model
constraints. Note that, although the resulting shape is plausible, the
inferred locations of the remaining 7 points are not very accurate. The next
step is to try including candidates from the remaining landmarks. The nose
tip is the one that achieves the lowest cost of inclusion, and is therefore
added. This considerably improves the accuracy of the inferred shape. Inclusions
continue, one at a time, until reaching 9 candidate-based landmarks. All
remaining candidates are checked, but in this case none of them produces a
plausible instance with 10 candidates. Hence, the final positions for the
remaining two landmarks are determined by inference.
We
demonstrated the accuracy of the proposed method in a set of 144 facial scans
acquired by means of a hand-held laser scanner in the context of clinical craniofacial
dysmorphology research [Hennessy
2002]. Using spin images [Johnson 1999] to describe the geometry and targeting 11 facial
landmarks, we obtained an average error of approximately 3 mm, which compares
favorably with other state of the art approaches based on geometric
descriptors. Further
details are provided in the following publication: |
|
||||||||||||||||||||||||||||||||||||||
|
|
F.M. Sukno, J.L.
Waddington and P.F. Whelan; “3D Facial Landmark Localization using
Combinatorial Search and Shape Regression” Proc. 5th ECCV Workshop on
Non-Rigid Shape Analysis and Deformable Image Alignment, Firenze, Italy, LNCS vol. 7583, pp 32-41, 2012. |
|
|||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||
|
Asymmetry Patterns Shape Contexts |
|
||||||||||||||||||||||||||||||||||||||
|
We presented a
new family of 3D geometry descriptors based on asymmetry patterns from the
popular 3D Shape Contexts (3DSC) [Frome 2004]. Our approach resolves the azimuth ambiguity of
3DSC, thus providing rotational invariance, at the expense of a marginal
increase in computational load, outperforming previous algorithms dealing
with azimuth ambiguity. We build on a
recently presented measure of approximate rotational symmetry in 2D [Guo 2010], defined as the overlapping area between a shape
and rotated versions of itself. We show that such a measure can be extended
to 3DSC and derive asymmetry based on the absolute differences between
overlapping bins of the descriptor and rotated versions of itself. Both
measures depend of the rotation angle but not on the selection of the origin
of azimuth bins, which allows us to obtain patterns that capture the
rotational asymmetry of the descriptor over the azimuth but are invariant to
the rotation of its bins. The asymmetry
patterns can be defined in a variety of ways, depending on the spatial
relationships that need to be highlighted or disabled. Thus, we define
Asymmetry Patterns Shape Contexts (APSC) from a subset of the possible
spatial relations present in the spherical support region; hence they can be
thought of as a family of descriptors that depend on the subset that is
selected. The
possibility to define APSC descriptors by selecting diverse spatial patterns
from a 3DSC has two important advantages: 1) choosing the appropriate spatial
patterns can considerably reduce the errors obtained with 3DSC when targeting
specific types of points; 2) once an APSC descriptor is built, additional
ones can be built with only incremental cost. Therefore, it is possible to
use a pool of APSC descriptors to maximize accuracy without a large increase
in computational cost. We have
experimentally showed that it is possible to attain rotationally invariant
shape contexts that obtain comparable accuracy to 3DSC for the localization
of craniofacial landmarks and remarkably outperform 3DSC for specific points
like the outer eye corners and nose corners [Sukno 2013a]. Further
details are provided in the following publication: |
|
||||||||||||||||||||||||||||||||||||||
|
|
F.M. Sukno, J.L.
Waddington and P.F. Whelan; “Rotationally Invariant 3D Shape Contexts Using
Asymmetry Patterns” Proc. 8th International Conference on
Computer Graphics Theory and Applications, Barcelona,
Spain, pp 7–17, 2013 – BEST PAPER AWARD |
|
|||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||
|
Compensating inaccurate annotations to train 3D
facial landmark localization models |
|
||||||||||||||||||||||||||||||||||||||
|
The results
from automatic methods for landmark localization in 3D indicate that the most
prominent facial landmarks can be located with errors varying between 3 and 6
mm, with some advantage to algorithms incorporating texture over those based
purely on geometric features. In global terms, targeting sets between 5 and
15 landmarks, the overall errors reported are typically above 4 mm. However,
these errors seem considerably higher than the localization accuracy that
might be achieved by means of manual annotations. Indeed, results from
clinical research suggest that the errors of manual annotations for several
facial landmarks can be as low as 1 to 2 mm. Recently, we
have shown that the above discrepancy could partly be explained due to the
lack of consistency of the manual annotations currently available for public
databases such as FRGC (Face Recognition Grand Challenge [Phillips 2005]). In contrast to traditional measures of accuracy,
such as inter- and intra-observer variability, we base our analysis on the
consistency of annotations by comparing the inter-landmark distances of
replicates (i.e. different scans from the same individual). It is widely
accepted that, except for the lower part of the face (mouth and chin), the pairwise distances between anthropometric landmarks
should remain unchanged for different scans of the same individual. Thus, we
can objectively measure how consistent are the annotations on a given dataset
without the need to generate repeated markups. Notice that
consistency of annotations is a necessary but not sufficient condition for
accuracy. Hence, lack of consistency implies lack of accuracy, with negative
effects not only on the evaluation results but also on the accuracy of any
model that is created using these annotations as a training set. The latter
relates to the problem of learning with noisy data, which has been
extensively studied in machine learning. The problem of inaccurate
annotations can be thought of as class-label noise (i.e. the wrong
coordinates in the facial scan are labelled as the
ground truth landmark position), as opposed to attribute noise which occurs
when the uncertainty affects primarily the extracted features (e.g.
acquisition noise). It has been
shown that the impact of class-label noise in learning algorithms is twofold:
1) it reduces the classification accuracy, and 2) it increases the complexity
of the classifier (when this is allowed by the algorithm, e.g. if using
support vector machines or decision trees). A popular approach to mitigate
these effects has been trying to identify (and eliminate) the samples that
are mislabelled. An interesting
difference in our case is that for each mislabelled
sample we certainly know that there is a correct sample readily available.
That is, a set of coordinates incorrectly labelled
as the ground truth position of the nose tip could be ideally replaced by the
correct set of coordinates, which are hopefully not too far away. Thus, we do
not need to discard these samples but we may actually attempt to correct
them. With this in mind, we presented an algorithm that aims to automatically
correct the annotations on a training set [Sukno 2013b]. It works under the hypotheses that the majority
of annotations are approximately correct and that a local geometry descriptor
can be used to estimate corresponding points across different surfaces. The
corrected annotations are obtained as those with the Least Squared
Corrections of Uncertainty (LSCU) from the initial ones that achieve maximum
similarity of the local geometry descriptor for a given uncertainty radius.
This radius is the only parameter of the algorithm and indicates the maximum
noise level that we expect from the input annotations.
Experiments on
a set of noisy annotations publicly available for 100 scans in the FRGC
database showed that models built from annotations corrected by LSCU were
significantly more accurate than models built from the original annotations.
The only parameter of the algorithm, the uncertainty radius, controls the
maximum displacement that is allowed for the corrections and we showed that
its choice has a fairly limited impact. Results from the public annotations
were also compared to our own set of manual annotations (available here). We objectively
showed that the latter has higher consistency, which allowed construction of
more accurate models. Applying LSCU to this set of cleaner annotations did
not produce significant changes, which suggests that the algorithm does not
distort the input data. Additionally, we showed that by applying LSCU to the
public annotations, it is possible to build models that obtain accuracy
similar to those built on our own set of cleaner annotations. Further
details are provided in the following publication: |
|
||||||||||||||||||||||||||||||||||||||
|
|
F.M. Sukno, J.L.
Waddington and P.F. Whelan; “Compensating inaccurate annotations to train 3D
facial landmark localization models” Proc. FG Workshop on 3D Face Biometrics,
Shanghai, China, pp 1-8, 2013. |
|
|||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||
|
References |
|
||||||||||||||||||||||||||||||||||||||
|
[Frome 2004] A. Frome, D. Huber, R., Kolluri
et al. (2004). Recognizing
objects in range data using regional point descriptors. In Proc.
European Conference on Computer Vision, pages 224–237, 2004. [Guo 2010] Q. Guo, F. Guo, and J. Shao (2010). Irregular
shape symmetry analysis: Theory and application to quantitative galaxy
classification. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 32(10):1730–1743, 2010. [Johnson 1999] A.E. Johnson and M. Hebert (1999). Using
spin images for efficient object recognition in cluttered 3D scenes.
IEEE Transactions on Pattern Analysis and Machine Intelligence 21(5):
433–449, 1999. [Hennessy
2002] R.H. Hennessy, A. Kinsella,
and J.L. Waddington (2002). 3D
laser surface scanning and geometric morphometric
analysis of craniofacial shape as an index of cerebro-craniofacial
morphogenesis: initial application to sexual dimorphism. Biological
Psychiatry, 51(6):507–514. 2002. [Phillips
2005] P.J. Phillips, P.J. Flynn, T. Scruggs et al.
(2005) Overview
of the face recognition grand challenge. In Proc. IEEE Int. Conf. on
Computer Vision and Pattern Recognition, vol 1, pp.
947–954, 2005. [Sukno 2012a] F.M. Sukno, J.L Waddington, and P.F. Whelan. 3D Facial
Landmark Localization Using Combinatorial Search and Shape Regression. ECCV Workshop on Non-Rigid Shape Analysis
and Deformable Image Alignment, LNCS vol. 7583, pp 32–41, 2012. [Sukno 2013a] F.M. Sukno, J.L Waddington, and P.F. Whelan. Rotationally invariant 3D shape contexts
using asymmetry patterns. In Proc. Int. Conf. on Computer Graphics
Theory and App., pages 7–17, 2013. [Sukno 2013b] F.M. Sukno, J.L Waddington, and P.F. Whelan. Compensating
inaccurate annotations to train 3D facial landmark localization models,
FG Workshop on 3D Face Biometrics Workshop, pp 1-8, 2013. |
|
||||||||||||||||||||||||||||||||||||||
|
|